

虽然大型语言模型 (LLM) 中的“L”暗示了庞大的规模,但实际情况更为细致。有些 LLM 包含数万亿个参数,而另一些 LLM 则在参数少得多的情况下有效运行。
了解一些真实世界的示例以及不同模型大小的实际影响。
LLM 模型大小和尺寸类别
作为 Web 开发者,我们倾向于将资源的大小视为其下载大小。而模型的记录大小指的是其参数的数量。例如,Gemma 2B 表示具有 20 亿参数的 Gemma 模型。
LLM 可能有数十万、数百万、数十亿甚至数万亿个参数。
较大的 LLM 比其较小的同类模型拥有更多的参数,这使得它们能够捕获更复杂的语言关系并处理细致入微的提示。它们通常也在更大的数据集上进行训练。
您可能已经注意到,某些模型大小(如 20 亿或 70 亿)很常见。例如,Gemma 2B、Gemma 7B,或 Mistral 7B。模型尺寸类别是近似的分组。例如,Gemma 2B 大约有 20 亿个参数,但并非完全如此。
模型尺寸类别提供了一种衡量 LLM 性能的实用方法。可以将它们视为拳击中的体重级别:同一尺寸类别中的模型更具可比性。两个 2B 模型应提供相似的性能。
也就是说,对于特定任务,较小的模型可以达到与较大模型相同的性能。

虽然大多数最新的最先进 LLM(如 GPT-4 和 Gemini Pro 或 Ultra)的模型大小并非总是公开,但据信它们有数千亿或数万亿个参数。

并非所有模型都在其名称中都标明了参数数量。有些模型在其名称后附加了版本号。例如,Gemini 1.5 Pro 指的是模型的 1.5 版本(版本 1 之后)。
是否为 LLM?
模型小到什么程度就不能称为 LLM 了?在 AI 和 ML 社区中,LLM 的定义可能有些模糊。
有些人认为只有具有数十亿参数的最大模型才是真正的 LLM,而较小的模型(如 DistilBERT)则被认为是简单的 NLP 模型。另一些人则将较小但仍然强大的模型也纳入 LLM 的定义,例如 DistilBERT。
用于设备端用例的较小 LLM
较大的 LLM 需要大量的存储空间和大量的计算能力才能进行推理。它们需要运行在具有特定硬件(如 TPU)的专用强大服务器上。
作为 Web 开发者,我们感兴趣的一件事是模型是否足够小,可以下载并在用户的设备上运行。
但是,这是一个难以回答的问题!截至今天,您没有简单的方法知道“此模型可以在大多数中端设备上运行”,原因如下:
- 设备功能在内存、GPU/CPU 规格等方面差异很大。低端 Android 手机和 NVIDIA® RTX 笔记本电脑截然不同。您可能有一些关于用户所用设备的数据点。我们还没有用于访问 Web 的基准设备的定义。
- 模型或其运行所在的框架可能经过优化,可在特定硬件上运行。
- 没有程序化的方法来确定特定的 LLM 是否可以下载并在特定的设备上运行。设备的下载能力取决于 GPU 上有多少 VRAM 以及其他因素。
但是,我们有一些经验知识:如今,一些参数在数百万到数十亿范围内的模型可以在浏览器和消费级设备上运行。
例如:
- Gemma 2B 与 MediaPipe LLM 推理 API(甚至适用于仅 CPU 的设备)。尝试一下。
- DistilBERT 与 Transformers.js。
这是一个新兴领域。您可以期待格局不断发展:
- 随着 WebAssembly 和 WebGPU 的创新、WebGPU 支持在更多库中落地、新的库和优化,预计用户设备将越来越能够有效地运行各种大小的 LLM。
- 预计通过新兴的模型缩小技术,更小、性能更高的 LLM 将变得越来越普遍。
较小 LLM 的注意事项
当使用较小的 LLM 时,您应始终考虑性能和下载大小。
性能
任何模型的功能都很大程度上取决于您的用例!针对您的用例微调的较小 LLM 可能比更大的通用 LLM 表现更好。
但是,在同一模型系列中,较小的 LLM 的能力不如其较大的同类模型。对于相同的用例,当使用较小的 LLM 时,您通常需要做更多提示工程工作。
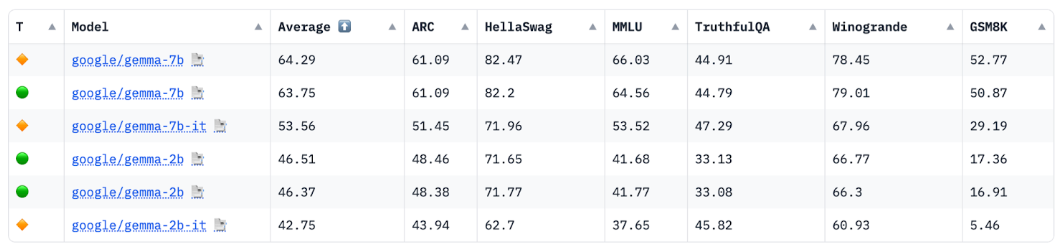
来源:HuggingFace Open LLM Leaderboard,2024 年 4 月
下载大小
更多参数意味着更大的下载大小,这也影响了模型(即使被认为是小的)是否可以合理地下载以供设备端使用。
虽然有一些技术可以根据参数数量计算模型的下载大小,但这可能很复杂。
截至 2024 年初,模型下载大小很少被记录。因此,对于您的设备端和浏览器内用例,我们建议您通过经验来查看下载大小,可以在 Chrome DevTools 的Network面板或其他浏览器开发者工具中查看。

Gemma 与 MediaPipe LLM 推理 API 一起使用。DistilBERT 与 Transformers.js 一起使用。
模型缩小技术
存在多种技术可以显着减少模型的内存需求:
- LoRA (Low-Rank Adaptation):微调技术,其中预训练权重被冻结。阅读有关 LoRA 的更多信息。
- 剪枝:从模型中移除不太重要的权重以减小其大小。
- 量化:将权重的精度从浮点数(例如,32 位)降低到较低位表示(例如,8 位)。
- 知识蒸馏:训练一个较小的模型来模仿较大的预训练模型的行为。
- 参数共享:对模型的多个部分使用相同的权重,从而减少唯一参数的总数。