

发布时间:2025 年 1 月 30 日
与原生应用程序一样,Web 上的许多 WebAssembly 应用程序都受益于多线程。多线程可以并行完成更多工作,并将繁重的工作从主线程转移出去,以避免延迟问题。直到最近,多线程应用程序仍然存在一些常见的痛点,这些痛点与分配和 I/O 相关。幸运的是,Emscripten 中的最新功能可以极大地帮助解决这些问题。本指南展示了这些功能如何在某些情况下带来 10 倍或更多的速度提升。
扩展
下图显示了纯数学工作负载中的高效多线程扩展(来自本文中我们将使用的基准)
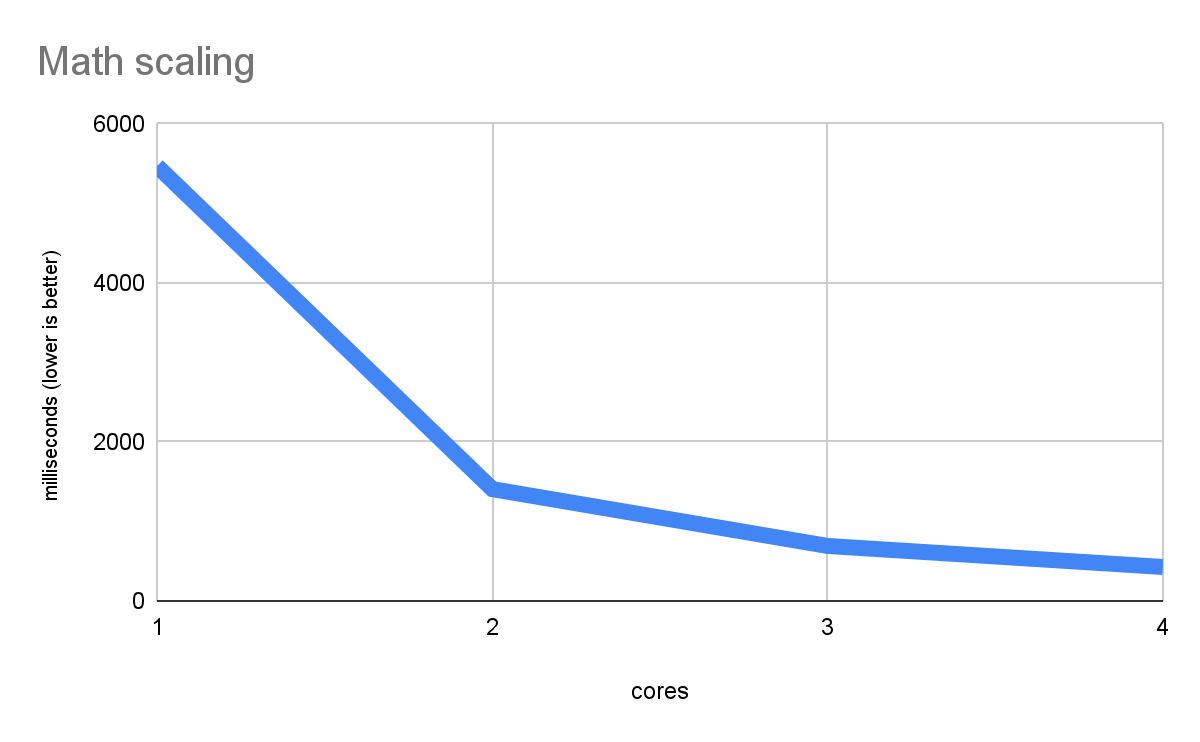
这衡量的是纯计算,每个 CPU 核心都可以独立完成,因此性能会随着核心数量的增加而提高。这种性能更快的下降曲线正是良好扩展的体现。它表明,尽管 Web 平台使用 Web Worker 作为并行化的基础,使用 Wasm 而不是真正的原生代码,以及其他可能看起来不太理想的细节,但它仍然可以很好地执行多线程原生代码。
堆管理:malloc/free
malloc 和 free 是所有线性内存语言(例如 C、C++、Rust 和 Zig)中关键的标准库函数,用于管理所有非完全静态或位于堆栈上的内存。Emscripten 默认使用 dlmalloc,这是一个紧凑但高效的实现(它也支持 emmalloc,它更紧凑但在某些情况下速度较慢)。但是,dlmalloc 的多线程性能受到限制,因为它在每次 malloc/free 上都采用锁(因为只有一个全局分配器)。因此,如果您在多个线程中同时进行大量分配,则可能会遇到争用和速度变慢的情况。以下是运行一个极其 malloc 繁重的基准测试时发生的情况
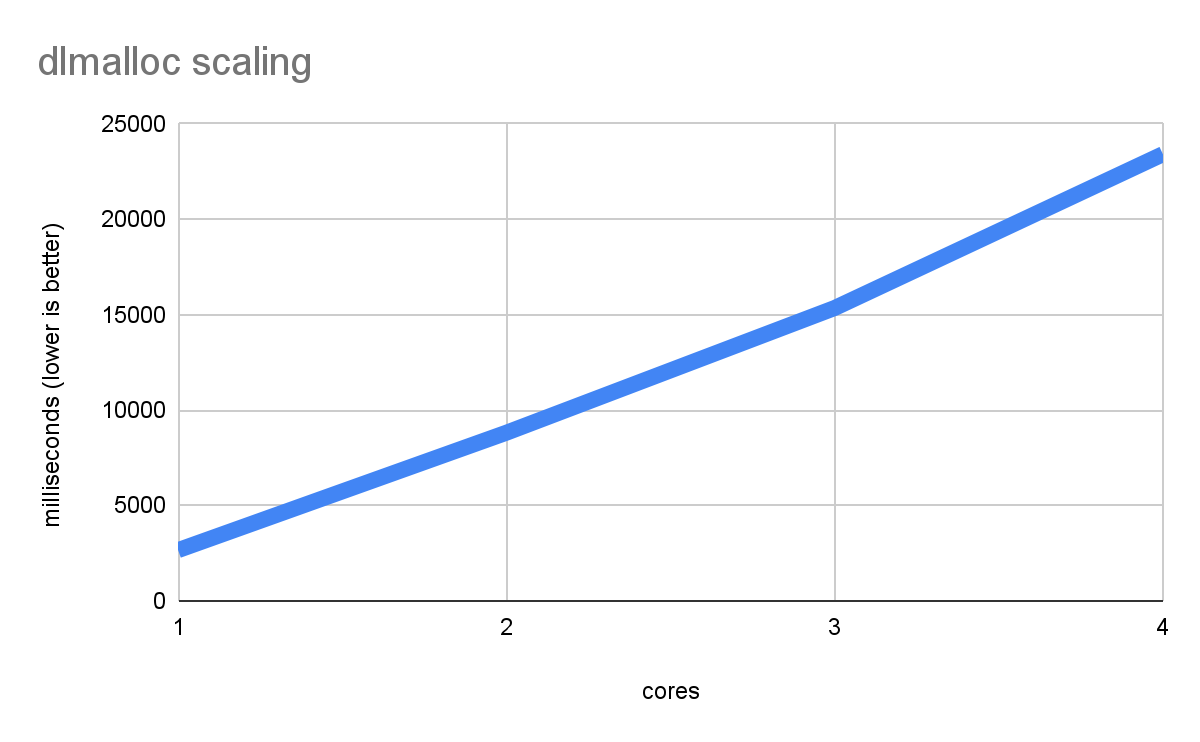
性能不仅没有随着核心数量的增加而提高,反而变得越来越差,因为每个线程最终都花费很长时间等待 malloc 锁。这是可能出现的最坏情况,但如果存在足够的分配,则可能会在实际工作负载中发生。
mimalloc
存在 dlmalloc 的多线程优化版本,例如 ptmalloc3,它为每个线程实现一个单独的分配器实例,避免争用。还存在其他几种具有多线程优化的分配器,例如 jemalloc 和 tcmalloc。Emscripten 决定专注于最新的 mimalloc 项目,这是一个来自 Microsoft 的设计精良的分配器,具有非常好的可移植性和性能。按如下方式使用它
emcc -sMALLOC=mimalloc
以下是使用 mimalloc 的 malloc 基准测试的结果
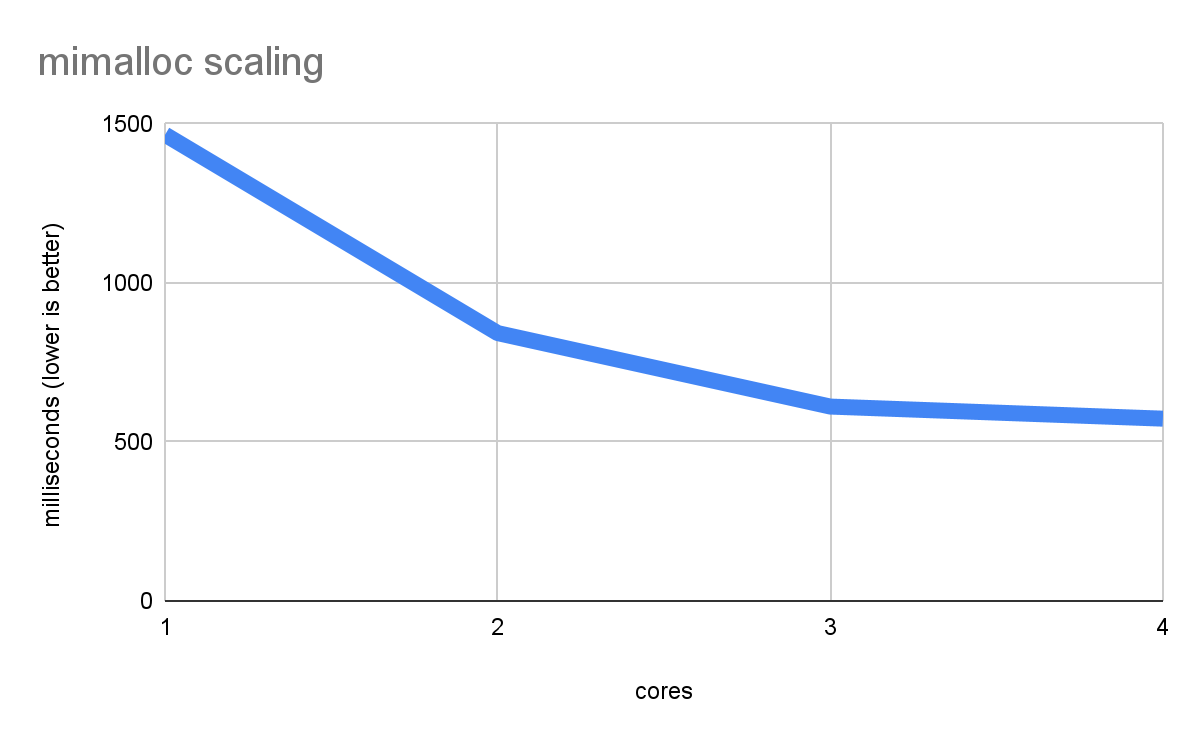
完美!现在性能可以有效地扩展,并且随着每个核心的增加而变得越来越快。
如果您仔细查看最后两个图表中单核性能的数据,您会发现 dlmalloc 花费了 2660 毫秒,而 mimalloc 仅花费了 1466 毫秒,速度提升了近 2 倍。这表明,即使在单线程应用程序上,您也可能会从 mimalloc 更复杂的优化中获益,但请注意,这会以代码大小和内存使用量为代价(因此,dlmalloc 仍然是默认设置)。
文件和 I/O
许多应用程序出于各种原因需要使用文件。例如,加载游戏中的关卡或图像编辑器中的字体。即使像 printf 这样的操作也在底层使用文件系统,因为它通过将数据写入 stdout 来打印。
在单线程应用程序中,这通常不是问题,如果您只需要 printf,Emscripten 将自动避免链接完整的文件系统支持。但是,如果您确实使用文件,那么多线程文件系统访问会很棘手,因为文件访问必须在线程之间同步。Emscripten 中最初的文件系统实现称为“JS FS”,因为它是在 JavaScript 中实现的,它使用了仅在主线程上实现文件系统的简单模型。每当另一个线程想要访问文件时,它都会将请求代理到主线程。这意味着另一个线程会阻塞跨线程请求,主线程最终会处理该请求。
如果只有主线程访问文件,则此简单模型是最佳的,这是一种常见的模式。但是,如果其他线程进行读取和写入,则会出现问题。首先,主线程最终会为其他线程做工作,从而导致用户可见的延迟。然后,后台线程最终会等待主线程空闲才能完成它们需要的工作,因此事情会变得更慢(或者,更糟糕的是,如果主线程当前正在等待该工作线程,则可能会陷入死锁)。
WasmFS
为了解决这个问题,Emscripten 有一个新的文件系统实现 WasmFS。WasmFS 是用 C++ 编写并编译为 Wasm 的,这与最初的 JavaScript 文件系统不同。WasmFS 支持从多个线程进行文件系统访问,开销极小,因为它将文件存储在 Wasm 线性内存中,该内存在所有线程之间共享。现在,所有线程都可以以相同的性能进行文件 I/O,并且它们通常甚至可以避免相互阻塞。
一个简单的文件系统基准测试显示了 WasmFS 相对于旧 JS FS 的巨大优势。
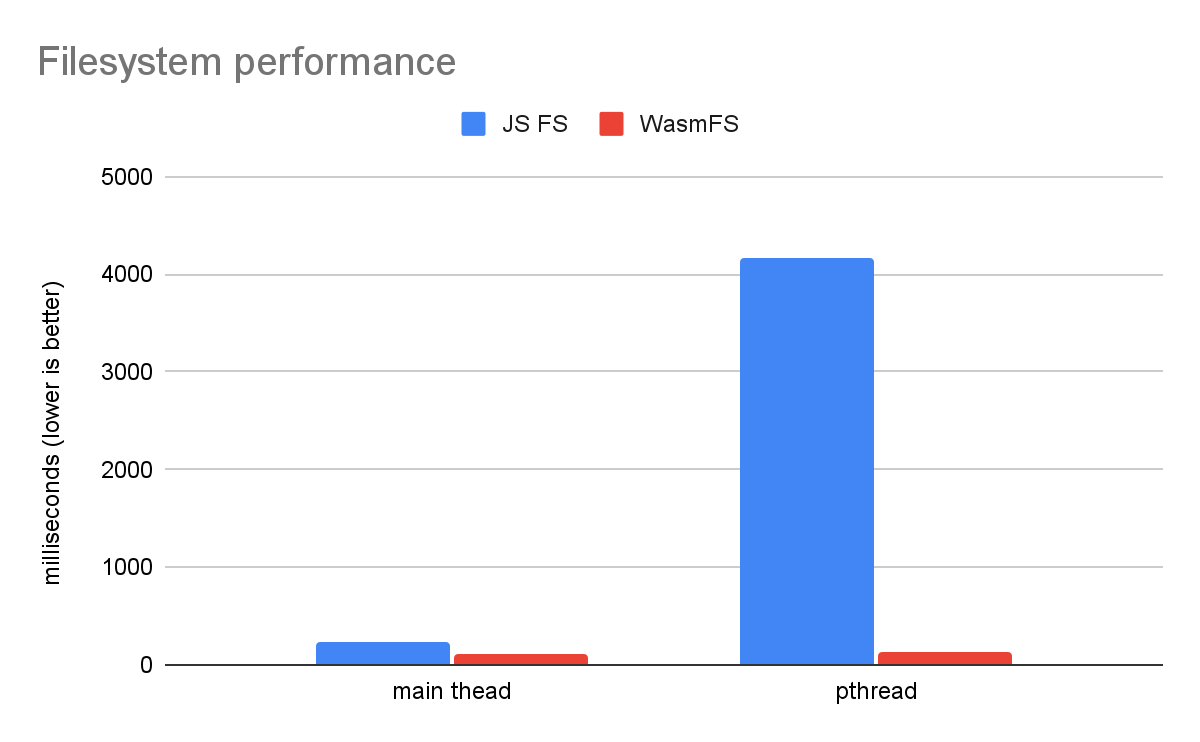
这比较了直接在主线程上运行文件系统代码与在单个 pthread 上运行文件系统代码。在旧的 JS FS 中,每个文件系统操作都必须代理到主线程,这使得它在 pthread 上慢了一个数量级以上!这是因为 JS FS 不仅仅是读取/写入一些字节,而是进行跨线程通信,这涉及锁、队列和等待。相比之下,WasmFS 可以从任何线程同等地访问文件,因此图表显示,主线程和 pthread 之间实际上没有区别。因此,在 pthread 上,WasmFS 比 JS FS 快 32 倍。
请注意,在主线程上也有差异,WasmFS 快 2 倍。这是因为 JS FS 为每个文件系统操作都调用 JavaScript,而 WasmFS 避免了这种情况。WasmFS 仅在必要时使用 JavaScript(例如,使用 Web API),这会将大多数 WasmFS 文件保留在 Wasm 中。此外,即使需要 JavaScript,WasmFS 也可以使用辅助线程而不是主线程,以避免用户可见的延迟。因此,即使您的应用程序不是多线程的(或者即使它是多线程的,但仅在主线程上使用文件),您也可能会看到使用 WasmFS 带来的速度提升。
按如下方式使用 WasmFS
emcc -sWASMFS
WasmFS 已在生产环境中使用,并被认为是稳定的,但它尚不支持旧 JS FS 的所有功能。另一方面,它确实包含一些重要的新功能,例如支持源私有文件系统(OPFS,强烈推荐用于持久存储)。除非您恰好需要尚未移植的功能,否则 Emscripten 团队建议使用 WasmFS。
结论
如果您的多线程应用程序执行大量分配或使用文件,那么您可能会通过使用 WasmFS 和/或 mimalloc 获益匪浅。两者都可以在 Emscripten 项目中轻松尝试,只需使用本文中描述的标志重新编译即可。
即使您不使用线程,您也可能想尝试这些功能:如前所述,更现代的实现附带的优化在某些情况下即使在单核上也很明显。